So here's an idea - what if a new student to Houdini approached the process like learning a language? There are 2 ideas that I think new users to Houdini could benefit from. The first is learning the 20 most common nodes in the SOP context first. This is similar to language learners starting with a frequency list of the 2000 most common words in a chosen language. A learner can achieve 85% proficiency in a language with those words and 75% with as little as 1350 (out of almost 1 million in the English language). I think the same principle could apply to learning Houdini. If the student is comfortable with certain nodes first they would be more comfortable building basic networks quicker.
The second language learning idea is to learn common sentences or phrases to understand the structure of the language and learn basic combinations. So start with simple phrases (node trees) and progress to more complicated examples later on.
I reached out to Sidefx and they were kind enough to provide me with a list of the 50 most common nodes in SOP's not including HDA's. The top 20 were:
- xform
- delete
- null
- geo
- merge
- group
- color
- attribwrangle
- sphere
- polyextrude
- box
- objectmerge
- file
- copy
- scatter
- grid
- blast
- mountain
- attribvop
- pointwrangle
This was a good start but I wanted a little more data about the frequency of the node usage so I wrote a script that traversed a directory structure, counted up all the SOP nodes and generated a csv. If you're interested you can find a link to the script at the end of this post. The csv is ordered by frequency and includes the percentage each node is used and accumulative percentage. This gave me a way of figuring out where the diminishing returns were. And it turns out that roughly 23 nodes are used 80% of the time. It took another 20 nodes or so to reach the 90% mark. Here's a list based on the hip files on my personal computer.
| NodeType | Count | % | Total % | |
|---|---|---|---|---|
| 1. | Switch | 14893 | 12.33% | 12.33% |
| 2. | Transform | 11026 | 9.13% | 21.46% |
| 3. | Attribute VOP | 9371 | 7.76% | 29.22% |
| 4. | Null | 9366 | 7.75% | 36.97% |
| 5. | Attribute Wrangle | 7954 | 6.58% | 43.56% |
| 6. | Attribute Create | 5460 | 4.52% | 48.08% |
| 7. | Object Merge | 5327 | 4.41% | 52.49% |
| 8. | Merge | 4709 | 3.89% | 56.39% |
| 9. | Add | 3261 | 2.70% | 59.09% |
| 10. | File | 2992 | 2.47% | 61.57% |
| 11. | Group | 2846 | 2.35% | 63.93% |
| 12. | Alembic | 2572 | 2.13% | 66.06% |
| 13. | Blast | 1996 | 1.65% | 67.71% |
| 14. | Grid | 1927 | 1.59% | 69.31% |
| 15. | Sphere | 1792 | 1.48% | 70.79% |
| 16. | Line | 1668 | 1.38% | 72.17% |
| 17. | Copy | 1650 | 1.36% | 73.54% |
| 18. | VOP SOP | 1465 | 1.21% | 74.75% |
| 19. | Attribute Rename | 1450 | 1.20% | 75.95% |
| 20. | Facet | 1406 | 1.16% | 77.11% |
| 21. | Delete | 1400 | 1.15% | 78.27% |
| 22. | Tube | 1226 | 1.01% | 79.29% |
| 23. | Circle | 1143 | 0.94% | 80.24% |
If you look at the 2 lists you'll notice some differences. Sidefx has a much larger sample size and I have some personal preferences when choosing which node to use. My list also includes HDA's which is probably why the switch node is right at the top. It also occurred to me that users and studios might have a different top 20 based on the work they do and their specialities. For instance I'd be interested to see the difference between a game studio and a film studio.
So what can we learn from these lists? If you're new to Houdini I think focusing on examples that include these nodes will give you a good grasp of the basic building blocks. How many people feel completely overwhelmed when they are first introduced to Houdini? Even as someone who had been using the software for 3-4 months I had days when I thought I would never be able to remember or learn all the nodes that were available. This way a learner can focus on a small list knowing that it will cover most of their needs early on.
But just like a language, learning individual words doesn't help you effectively communicate until you start stringing them together. Which leads me to my second point. Learning basic phrases can teach the principles of the language and the context of the word. How does this translate into Houdini? Take the trusty copy SOP. On it's own it has no meaning, but combine it with a couple of the other common nodes and you can show the strength of proceduralism and how Houdini differs from other packages.
Copy Example
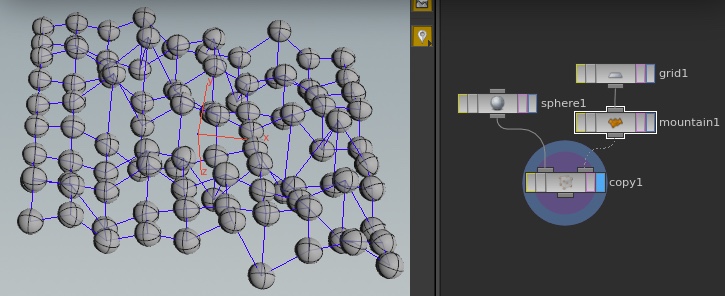
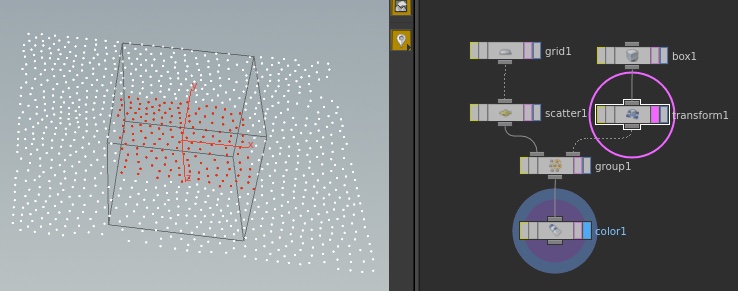
Staying with this idea of learning simple combinations let's look at the group node. By providing the user with a simple example of grouping components procedurally you create a fundamental building block and highlight the procedural nature of the package.
Procedural Grouping
I know that a lot of tutorials and classes already cover these fundamentals. What I'm attempting to do is provide an alternative mindset to the learning process and a framework within which to focus the learning process.
I started with SOP's because I'm of the opinion that anyone starting out in Houdini should get comfortable with procedural modelling first. It gives the user an opportunity to get comfortable with the package in a familiar context and understand some of the different approaches to creating a model. I think this idea of knowing the most common nodes could apply to other contexts as well. I think VOP's would be the next logical step.
On that note I think the one caveat to this approach for a beginner are VOP's and the wrangle nodes. Both are a rabbit hole all on their own. Thankfully there's generally a node that can cover most use cases for a beginner and avoid using something vex related.
I would like to continue my little investigation and produce a frequency list for nodes used in VOP's and functions used in wrangles. Just from anecdotal evidence I'm pretty sure there's a similar list of 20 or so nodes/functions that are used 80% of the time.
If you'd like to generate a frequency list based on your own hip files you can find my script with instructions here.